
Image classification with FastAI
Last weekend I started doing the Practical Deep Learning for Coders online course from the creator of the fastai python library, Jeremy Howard. I’d been wanting to start it for a few weeks but I saw a tweet by Jeremy saying that new versions of the library and the course would be released, and now that they are out I think it was worth the wait! I had seen the first lecture of the previous version of the course and even started the fun process of setting up a google compute account to run the code from the course using their free credits on signup, as the course recommended until then. But now for this version, they simplified and just recommend using the free options in Google Colab or Paperspace, which has been super easy to set up!
The course itself seems like it will be a very practical introduction to various applications of deep learning, while also going down into some detail on what the models are actually doing and how to use the many features contained inside fastai, while just requiring some knowledge of python. In the very first lesson, you get to train an image recognition model to reliably classify photos of cats vs dogs, using a dataset supplied by the course and with just a few lines of code that took less than a minute to run. But it really starts getting fun in the second lesson, where they start the process from the stage where the dataset gets built and take it all the way to training the model, checking its performance, and deploying it to a web application for prediction!
The example they give in the lecture is to build a dataset of images of different types of bears (black, grizzly, and teddy!) by downloading images via Bing Image searches*. After a bit of pain actually getting permission on my Microsoft account to use the image search API, it went pretty smoothly with just a few commands to download the images into separate folders for each class, get rid of anything with errors, assign labels, split train/validation sets, and actually train the model!
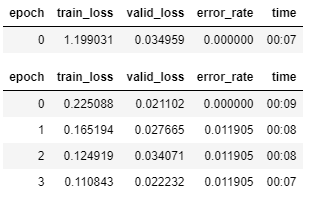
The table above tells me that from the first stage of training, the model was already getting 100% accuracy (0.0 error rate) on the 20% of the data set aside for validation. After 4 more epochs (rounds) of fine tuning the model, it actually got a little bit worse, but it was still an error rate of just over 1% which is great. The problem with having a near-perfect model straight from the beginning is that it doesn’t leave much room for improvement, which is when you actually get to learn something new!
Looking at a random sample of the images in the dataset (below), there’s some pretty obvious differences between teddy bears and the others, but even black and grizzly bears differ enough in fur colour that it’s super easy for us lowly humans to pick them out immediately.

My own dataset
Jeremy promises right at the beginning that it should be easy to get near state-of-the-art performance pretty easily with transfer learning in fastai and I know that the best models can now achieve superhuman performance, so I decided to make a dataset that I couldn’t classify reliably as a more fun challenge! While racking my brain for classes of images that would be easy to download by searching and were also hard to tell apart, I remembered some twitter memes about Hollywood actors named Chris that all look alike, but I couldn’t remember all their last names… so I turned to google’s ML models for help with the query “actors named chris that look similar”.
That gave me one of those suggested result boxes with the title “Who are the 5 chrises”: Evans, Hemsworth, Pratt, Pine, and Rock. I don’t quite agree that Chris Rock looks very similar to the other ones there, but I guess that must be a case of text processing models like OpenAI’s famous GPT-3 outputting wrong results that look just fine at a first glance! I decided to keep Rock in as a sort of internal control that I would be able to recognise, along with Pratt who I think I can recognise better from seeing him a lot in Parks and Recreation and Guardians of the Galaxy.
So I did a Bing query for each of the Chrises, which gave me about 150 images of each, with a few shown below. As I expected, I can recognise Pratt and Rock, the others are all the same person to my eyes that are pretty bad at facial recognition! I also spotted a black-and-white image in the set, which I’ve read can be a problem if there are not too many BW examples in the dataset, so I’ll keep an eye out for that after the model is trained.

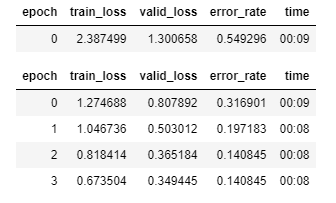
I took those images directly as they were into training, to see how the default fastai transfer learning settings would cope with this more challenging (I hoped!) dataset. To my delight, the model training (below) went quite a lot worse than it did for the bear classifier! An error rate of 14% is probably much better than I could do, but at least now I have room to improve on it…
My first step was to plot what is called the confusion matrix (below), which is just a table of all vs all labels, showing where predictions on the validation set were wrong. A perfect model would have all values along the diagonal, meaning that every label was correctly predicted. As I imagined, the model performed best for images of Chris Rock, only missing one Actual instance of his photos. Rock was also the label with the lowest number of mispredictions (3).

Then I looked at the examples in the dataset that had the highest losses, which means the model was least confident about its predictions for those images. I immediately spotted three possible sources of error:
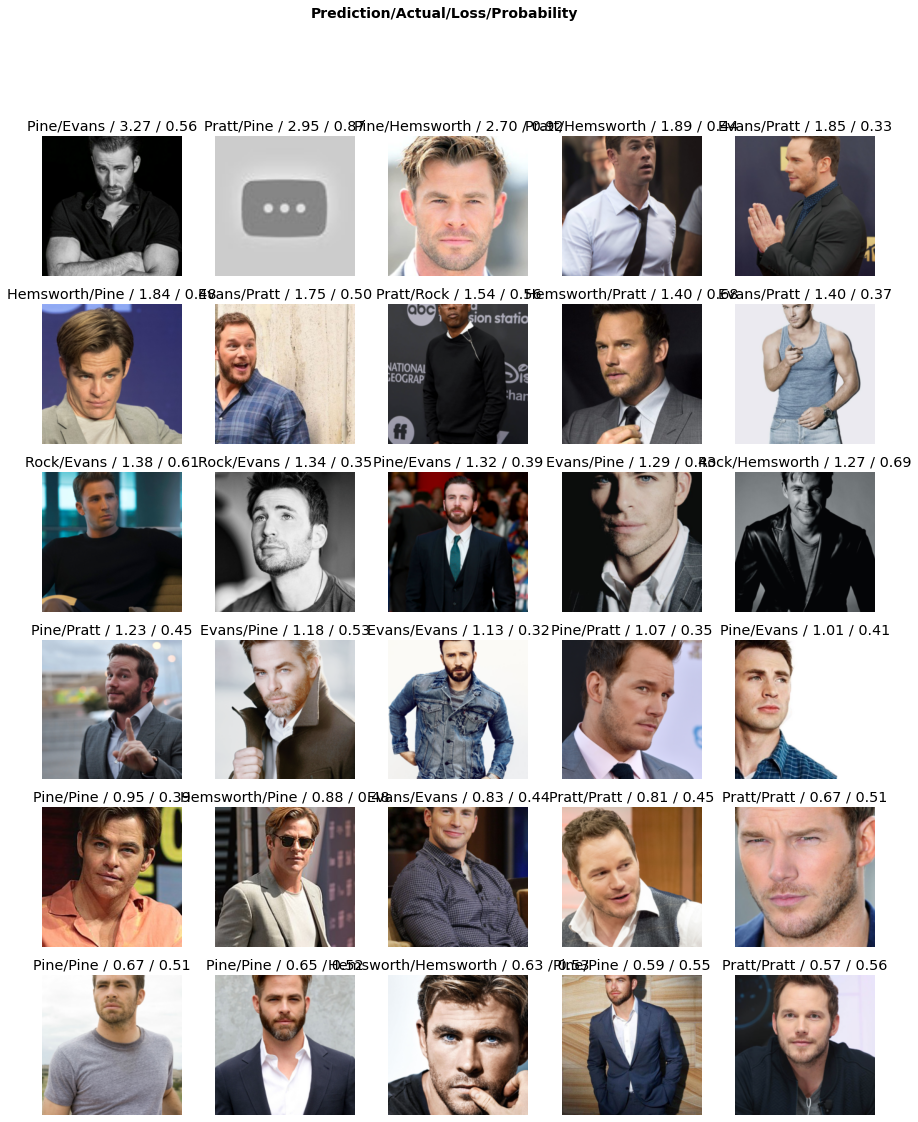
1 - My eyes can be bad at telling Chrises apart, but the second image in the first row definitely not a Chris. I make a note to drop that image from the set.**
2 - As I expected, there are 3 BW photos that got wrong predictions.
3 - The one mislabeled Chris Rock image only had half of his head in it, because the default setting I used to prepare the data set randomly crops the images to fit the 224x224 input format required by this model.
The latter two points may be fixed by data augmentation techniques, that increase the amount of data available for training image recognition without requiring more images to be downloaded. This is done by changing contrast/colour, randomly cropping in different ways, flipping, and rotating images so they’re still easily recognisable by human eyes but “look” very different to the neural network. In this case, I could simply download more images, but this is not always simple for a real dataset so I wanted to see how much improvement these techniques could produce.
Improving the model
I decided to just throw the kitchen sink at it, redoing the training with data augmentations and for 20 epochs (vs just 4 before), to see whether I could get the error rate below 10%.
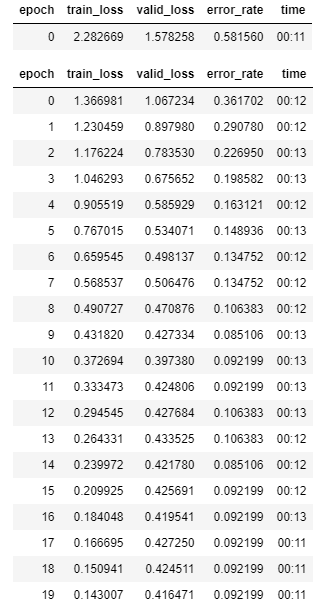
As you can see on the table above, I did get a final error rate below 10% by the end of this round of training. Even more interestingly, the best error rates were actually after epochs 8 and 14, and the final value was a touch worse. Looking over at the training and validation losses, the training loss was steadily decreasing in all epochs, but the validation loss reached a minimum at epoch 9, increased again and stabilised around 0.42. This suggests I’m actually starting to overfit the training set, leading to worse performance against the validation set. So, the best error rate I could get with these settings was around 8.5%.
Conclusions
I could probably keep tweaking to get better performance, but I didn’t split off a test set to compare between runs with different hyperparameters, so they wouldn’t be fair comparisons anyway. I think I’ve also had enough of staring at these photos of the various Chrises for a day…
More importantly, I noted down a few points to further explore what the fastai library is actually doing at various points and to dig into the documentation to find ways to change more settings or expose more useful data into its internal workings:
1 - I’m not sure whether the data augmentation option is adding multiple versions of the same image into the dataset. One way to find out would be to read some variable showing how many images are going to the GPU per batch of training and how many batches per epoch.
2 - If multiple versions are being added, can I control how many different versions are made?
3 - Is data augmentation being done on both training and validation sets?
4 - The default loss/error rate tables generated by fastai during training are all right when looking at small numbers of epochs, but it would be much better to find a way to store those values and plot them.
One of the big selling points for fastai is that, while picking sensible default settings for the various architectures and types of data, it’s also supposed to give users the freedom to dig into the lower levels and tweak anything they want. So this means I’ll spend some time tomorrow diving into the fastai docs and forums! Wish me luck!
Footnotes
* This is certainly the first time I’ve ever actually used Bing for anything and apparently Bing Image search is the best free way to get decent number of images via an API search!
** While scanning through the images to find that one that isn’t a photo at all, I also spotted two others that were just a bit of text and also a few that had more than one person on the image. I dropped all of those potential confounders from the dataset for the round of training with data augmentation.